最近、画像生成AI StableDiffusionが話題だが
「なんか英語ばっかりで難しくて諦めた」とか
「プログラミングみたいな話が出てきて全然分かんなかった」みたいな反応も多く
「結局ウェブサイトとかLINE Botで何度か試してみたけど、調整とか出来ないから飽きちゃった」という人も多い。
今回は初心者でも簡単に自分のWindowsパソコン上に『自分だけの無料で使い放題の画像生成AI環境』を作る方法を紹介しよう。
すごく簡単だし、多機能。この記事の通りにやれば英語もプログラミングの知識も不要。
GPU(グラボ・グラフィックボード・ビデオカード)が無いパソコンでも、時間はかかるがCPUで画像生成してくれるソフトだ。
もちろんゲーミングPCなどGPUを搭載しているパソコンならGPUを活用して高速に画像生成が出来る。
また本家StableDiffusionよりVRAM(GPUメモリ)の使用率が少ないのでロー・ミドルの4GBや6GB程度のVRAMのGPUでも画像生成が出来る。
それがこのStable Diffusion UIと言うソフトだ。※もちろん無料
https://github.com/cmdr2/stable-diffusion-ui
なんと自動でStableDiffusionの準備をして画像生成の環境を起動してくれる。便利なソフトだ。
ちなみに結構な容量、最低でも20GBくらいになるので、ハードディスクとか空き容量に余裕があるドライブに解凍するのがお勧めだ。
まずhttps://github.com/cmdr2/stable-diffusion-uiにアクセスしてDownload for Windowsをクリックしよう。


すると、こういうフォルダとファイルが出てくるので(これは構築したあとの画像なので、もっと少ないが)”Start Stable Diffusion UI.cmd”と言うWindowsコマンドファイルをダブルクリックして開こう。


回線速度やパソコンの性能によって変化するが、初めて起動した時は色んなデータをダウンロードするので数十分かかることも有る。
焦って閉じたりしないで放っておこう。
もちろんその間、パソコンは他のことに使っていても大丈夫だ。
なおStableDiffusionの準備が完了すれば、次回からは1分程度で起動するので安心して良い。
※但し何時間経っても止まってる様に見える時は1回閉じて開き直すのも手だ。
しばらく経ってStableDiffusionの準備が完了したら自動で普段使っているブラウザが立ち上がる。

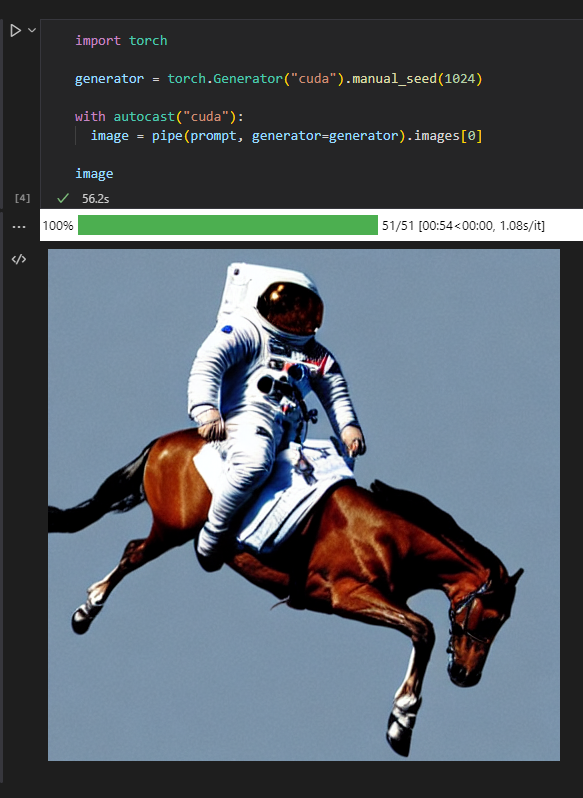
最初はテストを兼ねて”a photograph of an astronaut riding a horse”「馬に乗る宇宙飛行士の写真」と記入されているので 紫色の大きいボタン”Make image”を押してみよう。
しばらく待てば下記のように画像が生成されるはずだ。

ちなみに作りたい画像の文章をPrompt(プロンプト)と言う。
さっきの”a photograph of an astronaut riding a horse”がProntoに当たる。
次は翻訳ソフトなどを使って作りたい画像を英語にしてみよう。

そして翻訳された「Fountain in the center of a beautiful park」をStableDiffusionのEnter Promptに入力してMake Imageボタンを押す

一発目から思ってたより良いのが生成できた。
でも想像していたのと違うなら、Image Setting内のNumber of Image(total)の値を変えるのがおすすめだ。

例えばココを8に変えるとMake 8 Imageに変わる。放っといても同じPromptで8枚連続で画像生成してくれるわけだ。

しばらくすれば色んな噴水画像が出てくる。

そこから更にPromptを調整して想像に近づけたり。気に入った出来の画像を生成し直したり、高解像度化したりする応用機能も搭載されている。
ちなみに残りの4枚はこれだ。これらも個性があって良いね。

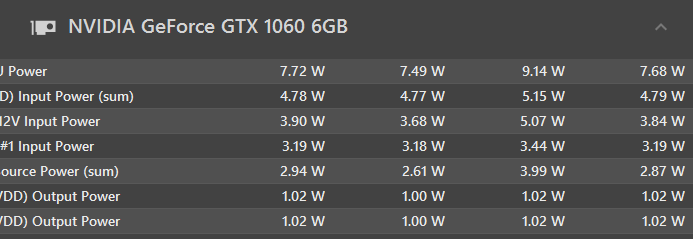
ちなみにタスクマネージャーでモニタリングしてみたところ

今回はGTX1060 6GBで実行したが、これなら3GBのグラボの人でも大丈夫そうだ。
次に「私のPCはゲーミングPCのじゃないからグラボとか載ってないよ」という人向けの解説だ。
上のSettingタブを押して下記の画像のUse CPU (not GPU)にチェックを入れ、ページ下部のSAVEボタンを押そう。これでGPUが載ってないパソコンでも画像生成ができる。
但し「warning: this will be *very* slow」と書いてある通り時間はかかる。

そしてさっきと同じ公園の噴水画像生成を今度はCPUで行おう。

クオリティは同等だが掛かった時間は309秒
さっきGPUで実行した時は43秒だったのでCPUでは7倍も時間がかかってしまった。
しかもCPUはcorei5 12400Fと言う、割りと新しくて、性能も良いCPUだ。
つまり画像生成はCPUよりGPUの方が遥かに向いていると言う事。
GPUを持っている人は是非GPUを活用してみて欲しい。
ついでに便利な機能としてパソコンに搭載している複数にGPUの中から、どのGPUを使うか選ぶSettingも有る。

実は私はGTX1660TIも持っていてGTX1060より高性能なのだが、StableDiffusionと相性が悪く、正常に画像が生成されなかったり、余計に多くVRAMを消費する問題が有る。
なので、最近使ってなかったGTX1060を引っ張り出してきて、開いているPCIExpressスロットに増設した。と言う訳だ。
自作PCをやっている人なら古いパーツを持っていたり、
ゲーミングノートPCの人はCPU内臓GPUとディスクリートグラフィックスのGPUが混載していたりする。
なので「StableDiffusionは起動したのに何故か画像生成が出来ない」と言う時は、このSettingで「使用するGPU」を手動で指定してからSAVEボタンを押そう。
そうすればStableDiffusionは指定したGPUで画像生成を行ってくれる。
あと私みたいにサブのGTX1060に画像生成をさせることでメインのGTX1660tiが使われていない状態ならば、GTX1660tiでPCゲームなどをしても問題ないということだ(多少パフォーマンスは落ちるが問題ない)
こうやってGPUを使い分ければ「ゲームしてる間にバックグラウンドで画像を何十枚も生成する」と行ことも出来る。
さて無事にStableDiffusionで画像生成は出来ただろうか?
今回は基本的な使い方と、簡単な設定の仕方を紹介したので、是非、思い思いの画像生成を楽しんでみて欲しい。
今回は初心者向けなので、他の機能や応用は、今後、別の記事で紹介していきたいと思う。